近期,IEEE國際計算機視覺與模式識別會議( Conference on Computer Vision and Pattern Recognition)CVPR 2025公布論文錄用結果,社交平臺Soul App技術論文《Teller: Real-Time Streaming Audio-Driven Portrait Animation with Autoregressive Motion Generation》(《基于自回歸動作生成的實時流式音頻驅動人像動畫系統》)被接收。
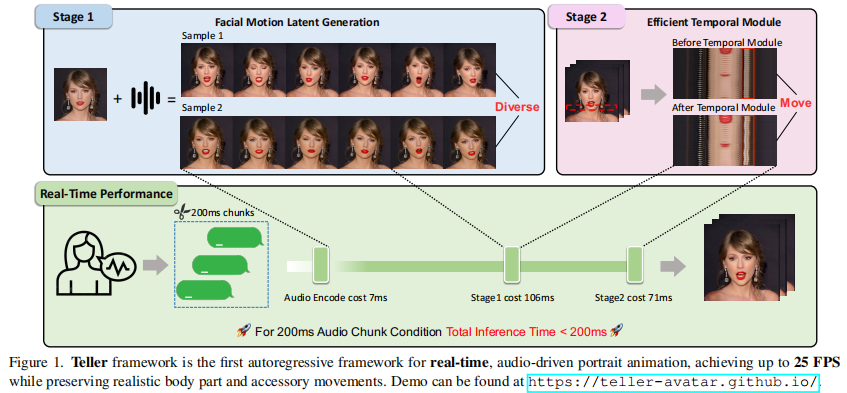
Soul App團隊在論文中提出了一個新的面向實時音頻驅動人像動畫(即Talking Head)的自回歸框架,解決了視頻畫面生成耗時長的行業挑戰外,還實現了說話時頭部生成以及人體各部位運動的自然性和逼真性。此次論文的入選,也證明了Soul App在推動多模態能力構建特別是視覺層面能力突破上取得了階段性成果。
CVPR是人工智能領域最具學術影響力的頂級會議之一,是中國計算機學會(CCF)推薦的A類國際學術會議。在谷歌學術指標2024年列出的全球最有影響力的科學期刊/會議中,CVPR位列總榜第2,僅次于Nature。
根據會議官方統計,本次CVPR 2025會議總投稿13008篇,錄用2878篇,錄用率僅為22.1%。相較2023年(25.8%)、2024年(23.6%),錄用率的持續下降也凸顯了CVPR不斷嚴格的審核標準,以及論文入選競爭的逐年激烈。
對Soul而言,研究成果再次入選國際頂級會議,證明了團隊在AI領域,特別是多模態方向的自研能力受到行業和學術界認可。2024年,Soul多模態情感識別研究論文《Multimodal Emotion Recognition with Vision-language Prompting and Modality Dropout》(《基于視覺語言提示與模態暫退的多模態情感識別》),入選ACM國際多媒體會議(ACM International Conference on Multimedia,ACM MM 2024)上組織的多模態與可靠性情感計算研討會MRAC 24。而在人工智能領域頂級的國際學術會議之一——國際人工智能聯合會議組織的第二屆多模態情感識別挑戰賽(MER24)上,Soul技術團隊還在SEMI(半監督學習)賽道獲得第一名。
作為較早思考將AI應用于社交領域的平臺,2016年Soul在上線后快速推出了基于AI算法的靈犀引擎,重構關系網絡發現的新模式,受到了廣大用戶的熱烈反饋,也堅定了平臺對AI持續投入的發展路線。2020年Soul開始啟動AIGC技術研發工作,在智能對話、語音、3D虛擬人等方面擁有前沿積累,并較早將重點聚焦在多模態方向。
自2023年推出自研語言大模型Soul X后,Soul已陸續上線了語音生成大模型、語音通話大模型、音樂生成大模型等語音大模型能力。目前,Soul AI大模型能力已整體升級為了多模態端到端大模型,支持文字對話、語音通話、多語種、多模態理解、真實擬人等特性,能夠實現更接近生活日常的交互對話和“類真人”的情感陪伴體驗。
在Soul看來,AI融入社交場景,除了需要AI介入內容表達以及關系的發現、建立、沉淀等環節,提高社交效率和社交體驗,同時也需要AI作為交互對象向個體提供情緒價值。而這要求團隊必須加快提升AI的感知能力和交互能力,即需要在語音、視覺、NLP的融合上下功夫,讓用戶能實時與具備形象、表情、記憶的 AI 多模態交互,而這也是更接近真實社交互動的方式。
在近期接受媒體采訪中,Soul App CTO陶明這樣解釋團隊關注視覺交互的邏輯,“從交互的信息復雜度來講,人和人面對面的溝通是信息傳播方式最快的,也是最有效的一種。所以我們認為在線上人機交互的過程當中,需要有這樣的表達方式。”
此次論文的研究成果正是Soul在融合視覺的多模態交互方向的積極探索。在論文中核心介紹了Soul團隊為提高視頻生成效率以及生成效果的擬人性、自然度所提出的創新方法。
該論文的動機是解構diffusion-base的模型關鍵步驟,用LLM和1step-diffusion進行重構,融合視頻模態,使SoulX大模型成為同時生成文字、語音、視頻的Unified Model。
具體而言,將talking head任務分成FMLG(面部Motion生成)、ETM(高效身體Movement生成)模塊。FMLG基于自回歸語言模型,利用大模型的強大學習能力和高效的多樣性采樣能力,生成準確且多樣的面部Motion。ETM則利用一步擴散,生成逼真的身體肌肉、飾品的運動效果。
實驗結果表明,相比擴散模型,該方案的視頻生成效率大幅提升,且從生成質量上來看,細微動作、面部身體動作協調度、自然度方面均有優異表現。
在Soul多模態大模型能力方向基礎上,該方案的提出將有助于AI構建實時生成的“數字世界”,并且能夠以生動的數字形象與用戶進行自然的交互。
此前,Soul基于自身的多模態大模型能力上線了語音交互功能,受到了用戶的熱烈討論和積極反饋。如今,從語音到視覺的模態升級,也意味著交互方式的顛覆式改變。
后續,Soul將把最新的AI能力盡快落地到站內多元場景中,如即將上線的實時視頻通話能力將融入平臺的AI虛擬人情感化陪伴體系“虛擬伴侶”、多對多互動場景“群聊派對”等功能中,進一步提升平臺AI虛擬人的交互能力,以及人機交互的在場感和情感溫度,為用戶帶來有趣、溫暖的社交體驗。
關鍵詞:








