典型應用場景、負載與需求
時序數(shù)據(jù)庫往往在金融與物聯(lián)網領域發(fā)揮重要作用。物聯(lián)網行業(yè)中,高頻寫入億級設備數(shù)據(jù)、對寫入數(shù)據(jù)自動去重、點查少量設備數(shù)據(jù)、以及統(tǒng)計分析大量設備數(shù)據(jù)都是比較常見的應用場景;金融行業(yè)中,實時寫入股票數(shù)據(jù)、對單只股票進行毫秒級點查、以及對大量股票進行統(tǒng)計分析與回測也需要高性能時序數(shù)據(jù)庫的支持。

研發(fā)人員參考上述典型應用場景,設計時序數(shù)據(jù)庫時會考慮如下因素:
?時序數(shù)據(jù)庫面臨極高的實時寫入負載,可達數(shù)億條每秒;
?時序數(shù)據(jù)庫面臨較高的查詢負荷;
?時序數(shù)據(jù)往往少量更新,經常批量刪除;
?控制成本。
因此,在設計 DolphinDB 數(shù)據(jù)庫時,我們采取了區(qū)別于傳統(tǒng) OLTP 數(shù)據(jù)庫的思路。
性能大PK
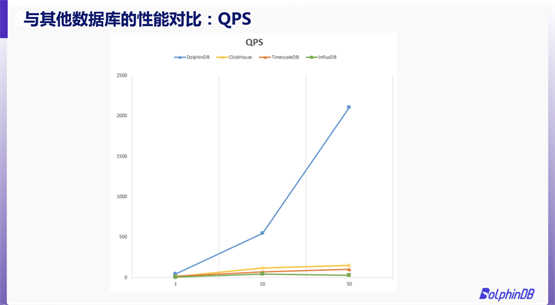
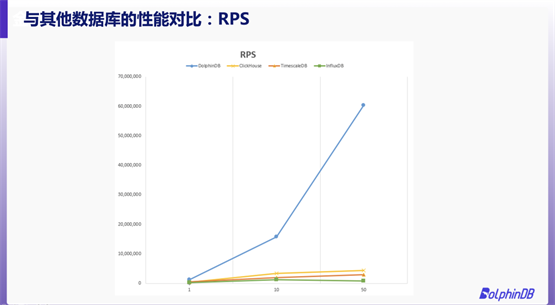
與市面上的熱門時序數(shù)據(jù)庫相比,DolphinDB 的性能究竟如何?我們用測試數(shù)據(jù)說話。
我們選擇了 NYSE Exchange TAQ Historical Data 作為測試數(shù)據(jù),選取 2007 年 8 月和 9 月的 Quotes 數(shù)據(jù)文件,原始數(shù)據(jù)大小為430 GB。我們采取點查的方式,查詢某一只股票一天的原始數(shù)據(jù)。事先隨機生成 100,000 條 SQL,所有數(shù)據(jù)庫按順序從集合中讀取 SQL。
本次測試中,我們重點關注 QPS(Query Per Second)與 RPS(Record Per Second)結果。通過圖片不難發(fā)現(xiàn),DolphinDB 的 QPS 和 RPS 均遠遠領先 ClickHouse、TimescaleDB 與 InfluxDB。在50個線程下并發(fā)查詢時,DolphinDB的 QPS 甚至可以達到其他數(shù)據(jù)庫的10倍以上。可以說,DolphinDB的存儲引擎高度適配了點查的應用場景。
WHY LSMT?
總體來說,數(shù)據(jù)庫的存儲引擎有兩大類解決方案:基于 page 和 B+ 樹的解決方案,與基于 Log Structured Merge Tree 的解決方案。之所以 LSMT 架構更適合時序數(shù)據(jù)的處理,是因為它具有以下特點:
?LSMT 能夠轉隨機寫為順序寫,能低成本承受極高的實時寫入負載;
?LSMT 可對 SortKey 進行排序,連續(xù)存儲同一條時間線的數(shù)據(jù),提高后續(xù)點查效率;
?LSMT 的數(shù)據(jù)文件不會繁瑣零碎,能夠高效支持大規(guī)模統(tǒng)計分析。
TSDB 設計詳解
基于 LSMT 架構,DolphinDB 推出了自研新存儲引擎 TSDB。TSDB 架構設計如下圖。
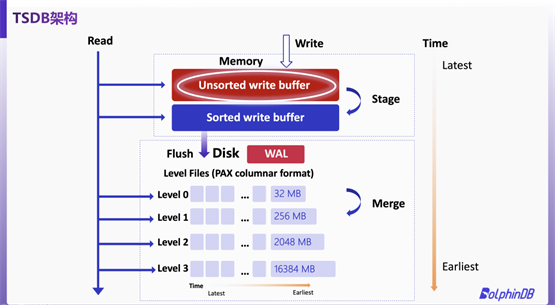
TSDB在存儲數(shù)據(jù)時,將數(shù)據(jù)拆分成多個數(shù)據(jù)塊(block),若查詢一條數(shù)據(jù),則只需解壓該條數(shù)據(jù)所在的數(shù)據(jù)塊,從而提升查詢效率。
事務支持、數(shù)據(jù)去重以及高頻更新
TSDB 支持基于快照隔離的事務。在每條數(shù)據(jù)寫入時記錄其版本號,查詢時僅查詢某版本號之前的數(shù)據(jù),因此保證用戶讀到的數(shù)據(jù)一致。
工業(yè)物聯(lián)網場景中,某個設備往往會在同一時間戳下產生多條數(shù)據(jù)。若數(shù)據(jù)亂序程度不大,重復數(shù)據(jù)會存儲在內存中,在刷盤時對數(shù)據(jù)進行排序及去重。如果數(shù)據(jù)亂序程度很大,TSDB 則會在查詢時去重。總體而言,去重對查詢性能的影響微乎其微。
而在 LSMT 架構中,數(shù)據(jù)總是從上到下寫入的,這與時序數(shù)據(jù)的時間戳遞增的特性完美符合。TSDB 根據(jù) LSMT 的這一特點,將更新的數(shù)據(jù)轉為追加寫,寫入到內存中,滿足高頻更新需求。
時間線膨脹問題該怎么解決?
當時間線非常多,而數(shù)據(jù)又非常稀疏(即每條時間線的數(shù)據(jù)很少)的時候,由于數(shù)據(jù)很碎片化,寫入和查詢的速度都會變慢、壓縮和大規(guī)模分析的效率也會降低。
TSDB 解決時間線膨脹的核心思路是“減少”時間線。具體來講,就是引入了一個新的參數(shù) sortKeyMappingFunction,讓用戶可以提供一個函數(shù)(或自定義的,或 DolphinDB 內嵌的函數(shù),如 hashBucket 函數(shù)),以此起到降維的效果。
不只是存儲
為了更好地挖掘并利用數(shù)據(jù)的價值,DolphinDB 為用戶提供了一站式分布式計算解決方案。用戶可以直接使用 SQL 進行分布式查詢,能夠靈活調用內置的1400余個分析函數(shù)。同時,DolphinDB 的編程語言簡單易用,代碼簡潔且易于維護。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據(jù)。
關鍵詞:









